The length of a finite string is a natural number. If a given Turing machine halts on the empty input, then the number of steps it performs before halting is a natural number. (A Turing machine halts if it reaches a halt state in a finite number of steps.) The concept of natural number is implicitly contained in the word “finite”. Is this circularity trivial?
Suppose that you have a consistent (but maybe unsound/dishonest) axiom system that claims that some given Turing machine would halt. Then this Turing machine defines a natural number in any model of that axiom system. To expose the trivial circularity, we can now use this natural number to define the length of a finite string of digits.
This idea was part of yet another attempt to explain how defining a natural number as a finite string of digits is circular. This post will explore whether this idea can be elaborated to construct a concrete non-standard model of the natural numbers, or more precisely of elementary function arithmetic, also called EFA. (This formal system is weaker then Peano arithmetic, because its induction scheme is restricted to formulas all of whose quantifiers are bounded. It is well suited as base system for our purpose, because all our proofs still go through without modification, and it is much easier to grasp which statements are independent of this system. Basically, it can prove that a function is total iff its runtime can be bounded by a finitely iterated exponential function.)
An attempt to explain that the circularity also occurs in practice
This section can be skipped. It is not a part of the main text. It tries to further illuminate the motivation for this post by quoting from a previous attempt to explain that circularity:
- Some people like to imagine natural numbers encoded in binary (least significant bit first) as finite strings of 0s and 1s. Note that this encoding uses equivalence classes of finite strings, since for example 10 and 100 both encode the number 1, i.e. the number of trailing zeros is irrelevant.
- But the word “finite” string already presupposes that we know how to distinguish between finite and infinite strings. So let us assume instead that we only have infinite strings of 0s and 1s, and that we want to encode natural numbers as equivalence classes of such strings.
- … (taken from 7.2 INTEGERS in http://www.wrcad.com/oasis/oasis-3626-042303-draft.pdf): “An unsigned-integer is an N-byte (N > 0) integer value. … the remaining seven bits in each byte are concatenated to form the actual integer value itself.”
- … Slightly generalising those schemes, we can say that the length is encoded as a prefix-free code, and the number is encoded in binary in a finite string of 0s and 1s of the given length.
- The vagueness of “finite” comes in because of the prefix-free code part of the encoding. … And using a non-prefix-free encoding for the length will only create more vagueness, not less.
The idea quoted in the introduction suggests to use a Turing machine as encoding for the length. In a certain sense, this is indeed a non-prefix-free encoding. In another sense, the Turing machine itself must also be encoded (as a finite string), so this does not refute point 5. But we will ignore this further implicit occurrence of “finite” in this post.
Interactions between partial lies, absolute truth, and partial truths
Since we want to construct a concrete non-standard model, we will use EFA + “EFA is inconsistent” as our axiom system. Let us call this axiom system nsEFA, as an acronym for non-standard EFA. Let M be a Turing machine for which nsEFA claims that it halts.
Let us assume that M has a push-only output tape, on which it will successively push the digits describing some number N. In the simplest case, there is just a single digit available, and we get an unary representation of N. More succinct representations are also possible, but this unary representation corresponds more closely to the number of steps performed by M. This correspondence is not exact, which raises an interesting issue:
Can it happen that M only outputs a finite number of digits in an absolute sense, but that nsEFA is undecided about the number of digits output by M?
There is no reason why this should not happen. But this would be bad for our purpose, since it could happen that M would represent 3 in one model of nsEFA, and 4 in another. We can prevent this from happening, by allowing only those M for which EFA can prove that M will halt or output infinitely many digits.
Are there other ways to prevent this from happening, which don’t use the trusted axiom system EFA in addition to nsEFA? We could rely on absolute truth, and only allow those M which halt or output infinitely many digits. (This is equivalent to a  sentence for given M, hence I don’t like it.) Or we could use EFA only via the class of functions which can be proved total in EFA, and require that nsEFA must prove for a concrete total function tf(n) from this class that M will not take more steps before halting or outputing the next digit than tf(“total number of steps of M when previous digit was output”). (This is fine for me, since nsEFA cannot lie about this without being inconsistent.)
sentence for given M, hence I don’t like it.) Or we could use EFA only via the class of functions which can be proved total in EFA, and require that nsEFA must prove for a concrete total function tf(n) from this class that M will not take more steps before halting or outputing the next digit than tf(“total number of steps of M when previous digit was output”). (This is fine for me, since nsEFA cannot lie about this without being inconsistent.)
Preventing the same issue for more succinct representations is a bit more tricky. For a positional numeral systems, it seems to make sense to only allow those M which halt or output infinitely many non-zero digits. But in this case, we could have a valid M which outputs 99999… (in decimal) or 11111… (in binary), but if we add 1, we get 00000… as output, which would be invalid. One way to fix this issue is to allow the digit 2 (in binary) or the digit A (in decimal), then we can use 02111… (in binary) or 0A999… (in decimal) as output. (We will call this additional digit the “overflow” digit, and the digit preceeding it the “maximal” digit.) It is also possible to weaken our requirements instead of having to invent new representation systems (see Appendix C: Weakening the requirements for succinct representations).
So we fixed this issue, but there is another even more serious problem.
Here is the problem: comparing numbers for equality
Let us call a Turing machine which satisfies the conditions described in the previous section an n-machine (because it defines a possibly non-standard natural number in any model of nsEFA). Let M and M’ be n-machines (using the unary representation as output, for simplicity). So both M and M’ define a number in any model of nsEFA. If nsEFA can prove that both M and M’ produce the same output, then the number defined by M and M’ is the same in any model. If nsEFA cannot prove this, then there will be a model where M and M’ define different numbers. Which is good, since this gives us an obvious way to define equality on the set of n-machines. So where is the problem?
Even so we know that M defines a number in any model of nsEFA, we don’t know whether it will define the same number in all models. But we just fixed this in the previous section, no? Well, we only fixed it for the case where M defines a standard natural number.
Comparing numbers from different models for equality is not always possible. For example, the imaginary unit i from one model of the complex number cannot be compared for equality with the negative imaginary unit -i from another model. But often it is possible to say that two numbers are different, even if they come from different models, just like i+1 and i-1 are definitively different.
It can happen that nsEFA can neither prove that M and M’ produce the same output, nor that they produce different output. So there will be a model where M and M’ define the same number, and a model where M and M’ define different numbers. It is unclear whether we should conclude from this that M defines different numbers in different models. An argument using standard natural numbers might be more convincing:
Can it happen that the remainder of the division of M with a standard natural number like 2 or 3 is different in different models of nsEFA?
Yes, it can happen, since nsEFA can be undecided about the exact result for the remainder. So we could have |M| = x+x in one model, and |M| = y+y + 1 in another model (where |M| is the number defined by M in the corresponding models). The trouble is that there is even an n-machine M’, which defines x in the first model and y in the other model. M’ gets constructed from M by outputting only every second digit output by M. One could argue that this means that M or M’ really defines different numbers in those two models.
(For example, let M be a machine which searches for a proof of a contradiction in EFA, which always outputs two digits for each step during the search. Finally, it outputs an additional digit iff the bit at a given finite position in the binary encoding of the found proof is set.)
Why not stop here? What should be achieved?
We must conclude that the idea to build a concrete non-standard model of EFA using only numbers which can be defined by some n-machine M will not work as intended. So why not end the post at this point?
First, it is important to understand what has already been achieved. The idea for this post (see Appendix A: Initial questions about circularity and the idea for this post) was just to use an axiom system like nsEFA and a Turing machine (satisfying suitable requirements based on nsEFA) to define a natural number in any model of nsEFA. This has been achieved. The idea had a more subtle part, which was to use the Turing machine mainly for defining the length of the string of digits, which forms the actual natural number. This part still needs more elaboration, which is one reason to go on with this post.
Another idea for the construction presented in this post has not yet been mentioned explicitly. There is an interesting definition on the top of page 5 of the nice, sweet, and short paper Compression Complexity by Stephen Fenner and Lance Fortnow:
Let  (“Busy Beaver of
(“Busy Beaver of  ”) be the maximum time for
”) be the maximum time for  to halt over all halting programs
to halt over all halting programs  of length at most . Let
of length at most . Let 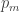 be the lexicographically least program of length at most that achieves running time.
be the lexicographically least program of length at most that achieves running time.
That encoding of by is nice: For fixed , it is just as efficient as the encoding by the first -bits of Chaitin’s constant, but much easier to explain (and decode, or rather it must not even be decoded). And for variable , the overhead over Chaitin’s encoding is just quadratic, so not too bad either. But the “time to halt” is slightly too sensitive to minor details of the program to allow arithmetic. Replacing “time to halt” by “length of unary output” is a natural modification of this encoding which allows computable arithmetic (addition, multiplication, exponentiation, minimum, maximum, and possibly more).
On the one hand, it is no surprise that the concrete definition of these arithmetic operations for the concrete encoding is possible. On the other hand, the section below which actually defined those operations (for unary output) got so long and convoluted that most of its content has been removed from this post. One reason why it got so convoluted is that an n-machine defines a natural number in any model of nsEFA, so we have to prove that our concrete definition of these arithmetic operations coincides (for numbers definable by n-machines) with the arithmetic operations already available in models of nsEFA. In addition, feedback by various people indicated that it should have been made clearer how the concrete definitions of the arithmetic operations are computable and independent of nsEFA, while equality depends on nsEFA and is only semi-decidable (i.e. computably enumerable instead of decidable/computable). And there is also the confusion why it should be relevant that the arithmetic operations are concrete and computable, if we are fine with much less for equality (see Appendix B: What are we allowed to assume?).
More relevant than that certain operation are computable and that some relations are semi-decidable is that some operations are not definable at all. We have seen this in the previous section for the remainder (of the division of M with a standard natural number like 2 or 3), if the definition of an n-machine uses unary output. One may wonder whether we showed this fact sufficiently rigorously, and how our definitions gave rise to this fact. The important part of our definitions is that we prevented that a non-standard number can be equal to a standard number. So if some operation has a standard number as result, and if this standard number is different in different models of nsEFA for two concrete n-machines, then that operation is not definable at all (with respect to the specific definition of n-machine).
What we will try to show when discussing numbers encoded as strings of digits is that the minimum and maximum operations are not definable, but that there are number representations for which the remainder (of the division of M with a standard natural number like 2 or 3) is definable (and computable). This is another reason why we want to explore more succinct representations, in addition to the unary representation. However, the corresponding section does not dig into the more basic details of doing arithmetic with these succinct representations (see Appendix E: More on the LCM numeral system), but only mentions the bare minimum of facts to indicate how its claims could be elaborated.
Finally, it should also be mentioned that this post failed to address certain questions (see Appendix D: Some questions this post failed to answer). The constructed structures seem to be models of Robinson arithmetic, which is not a big deal. The totality of the order relation fails. Therefore, the constructed structures cannot be models of any axiom system which would prove the totality of the order relation. But what about satisfying induction on open formulas? Probably not. Another question is how well the constructed structure can act as a substitute for the non-existent free model of nsEFA, or as a substitute for the non-existent standard model of nsEFA? Probably not very well.
Another point where this post failed is the very existence of this section. It has been added after this post was already published, because feedback indicated that this post failed to clearly communicate what it is trying to achieve. Together with introducing this section, many existing sections have been turned into appendices, and Appendix A has been newly added. Sorry for that, it is definitively bad style to alter a published post in such a way. But this post felt significantly more confusing than any other post in this blog, so not trying to improve it was also not a good option.
Translating the meaning of words into formulas
To add the numbers |M| and |M’| defined by M and M’ (using the unary representation as output), we construct a machine M” which first runs M and then runs M’. We claim that M” is an n-machine and that nsEFA proves |M|+|M’| = |M”|. So the number defined by M” is the sum of |M| and |M’| in any model of nsEFA. We denote M” by ADD(M,M’).
But what does it actually mean that nsEFA proves |M|+|M’| = |M”|? It can only prove (or even talk about) formulas in the first order language of arithmetic. The statement that M defines a number |M| means that we can mechanically translate M into a formula 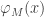 such that nsEFA proves
such that nsEFA proves 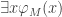 and
and 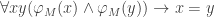 . To prove |M|+|M’| = |M”|, nsEFA must prove
. To prove |M|+|M’| = |M”|, nsEFA must prove 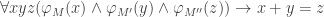 .
.
We use a formula  which describes the behavior of M. It says that M transitions in
which describes the behavior of M. It says that M transitions in  steps from the state
steps from the state  to the state
to the state 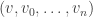 . This allows us to define
. This allows us to define  . Here the first component
. Here the first component  of the state is the line number of the program (or the internal state of the machine), and
of the state is the line number of the program (or the internal state of the machine), and  is the unique line of the program with a
is the unique line of the program with a  statement (or the unique internal halt state of the machine). We used the second component
statement (or the unique internal halt state of the machine). We used the second component 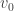 of the state as the push-only (unary) output tape.
of the state as the push-only (unary) output tape.
We also define the sentence HALT(M) . (A sentence is a formula with no free variables.) M halts if and only if HALT(M) is true for the standard model of the natural numbers. However, the standard model of the natural numbers is not a model of nsEFA. But HALT(M) is still meaningfull for nsEFA: If M halts and nsEFA would prove that HALT(M) is false, then nsEFA would be inconsistent.
. (A sentence is a formula with no free variables.) M halts if and only if HALT(M) is true for the standard model of the natural numbers. However, the standard model of the natural numbers is not a model of nsEFA. But HALT(M) is still meaningfull for nsEFA: If M halts and nsEFA would prove that HALT(M) is false, then nsEFA would be inconsistent.
Already the definition of nsEFA as EFA + “EFA is inconsistent” uses this translation. We take some machine C which searches for a proof in EFA of a contradiction, and add the formula HALT(C) to EFA as an additional axiom. The expectation is that nsEFA can then prove HALT(C’) for any other machine C’ searching for a contradiction in EFA. This will obviously fail if C’ does unnecessary work in a way that nsEFA cannot prove that it will still find a contradiction in EFA. For example, it could evaluate the Ackermann–Péter function A(m,n) at A(m,0) for increasing values of m between the steps of the search for a contradiction. Or C’ could use a less efficient search strategy than C, like looking for a cut-free proof, while C might accept proofs even if they use the cut rule.
(What if we use EFA + “ZFC in inconsistent” or EFA + “the Riemann hypothesis is false” as our axiom system? In the first case, the remarks on the efficiency loss of cut-free proofs are still relevant. In the second case, it would be hard to come up with different translations for which EFA cannot prove that they are equivalent. And if EFA could prove “the Riemann hypothesis is true”, then that axiom system would be inconsistent anyway.)
We also define the sentence LIVE(M):=HALT(M)∨
![(\exists svv_1\dots v_n\varphi_{M\to}(u,u_0,\dots,u_n;s;v,u_0+1,v_1,\dots,v_n)]](https://s0.wp.com/latex.php?latex=%28%5Cexists+svv_1%5Cdots+v_n%5Cvarphi_%7BM%5Cto%7D%28u%2Cu_0%2C%5Cdots%2Cu_n%3Bs%3Bv%2Cu_0%2B1%2Cv_1%2C%5Cdots%2Cv_n%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) (M halts or if M reaches state , then it reaches a state
(M halts or if M reaches state , then it reaches a state  ) which says that M will only take finitely many steps before it outputs another non-zero digit or halts.
) which says that M will only take finitely many steps before it outputs another non-zero digit or halts.
M is an n-machine if nsEFA proves HALT(M) and EFA proves LIVE(M). (EFA proves , independent of whether M is an n-machine or not. Namely EFA proves 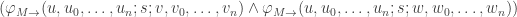
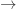
 , which expresses the fact that M is deterministic.) If nsEFA proves HALT(M), then nsEFA also proves . This is trivial, since our definition of HALT(M) turns out to be equivalent to .
, which expresses the fact that M is deterministic.) If nsEFA proves HALT(M), then nsEFA also proves . This is trivial, since our definition of HALT(M) turns out to be equivalent to .
Back to M”:=ADD(M,M’). How do we know that nsEFA proves HALT(M”) and EFA proves LIVE(M”)? It follows because EFA proves HALT(M) HALT(M’) HALT(M”) and LIVE(M) LIVE(M’) LIVE(M”). Details of are needed to say more. And nsEFA proves because EFA proves 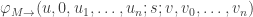
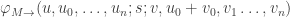 for any M which doesn’t query the register
for any M which doesn’t query the register 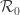 and only increases it.
and only increases it.
Using register machines for discussing EFA proofs
We defined ADD(M,M’) in the previous section. The definitions of MUL(M,M’) and POW(M’,M) will be more complicated, because |M’| might be zero (or one), hence the requirement that an n-machine does not run forever without outputting additional digits requires some care. We will also define SUB(M,x), DIV(M,x) and LOG(x,M). Here x must effectively be a standard natural number, for example a number defined by an n-machine for which EFA (instead of nsEFA) can prove that it halts.
In any case, we better define some machine architecture with corresponding programming constructs to facilitate the definition of those operations and the discussion of EFA proofs. A concrete machine architecture also facilitates the discussion of details of . Instead of Turing machines, we use register machines, since most introductory logic books use them instead of Turing machines. Typically, they first define register machines over an arbitrary alphabet 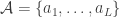 like
like
 |
If  then remove the last letter of the word in then remove the last letter of the word in  . Otherwise append the letter . Otherwise append the letter  to the word in . to the word in . |
 |
Read the word in . If the word is empty, go to  . Otherwise if the word ends with the letter , go to . Otherwise if the word ends with the letter , go to 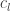 . . |
|
Halt the machine. |
and then focus on the case of the single letter alphabet  . For that case, we use a more explicit instruction set, which is easier to read:
. For that case, we use a more explicit instruction set, which is easier to read:
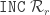 |
Increment . |
 |
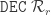 |
Decrement . If it is zero, then it stays zero. |
 |
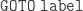 |
Go to the unique line where  is prepended. is prepended. |
 |
 |
If  , then go to , then go to  . . |
 |
|
Halt the machine. |
|
To avoid  , we define two simple control constructs:
, we define two simple control constructs:
We also define two simple initialization constructs:
Next we need constructs that allow us to express things like “a machine which runs M, and each time M would output a digit, it runs M’ instead”. To avoid that M’ messes up the registers of M, we allow symbolic upper indices on the registers like  ,
,  or even
or even  . We use this to define the program transform construction …
. We use this to define the program transform construction …
… and this section went on and on and on like this. It was long, the constructions were not robust, the proofs were handwavy, there were no nice new ideas, and motivations were absent. Maybe I will manage to create another blog post from the removed material. Anyway, back to more interesting stuff …
Succinct representations of natural numbers
The proposal from the introduction was to use the number of steps which a given Turing machine performs before halting to define the length of a finite string of digits. The observation that the unary representation fits into this framework too is no good excuse for not looking at more interesting strings of digits. So we have to look at least at a positional base b numeral system (for example with b=10 for decimal, or b=2 for binary). We will also look at the LCM numeral system, which is closely related to the factorial number system and to the primorial number system (see Appendix E: More on the LCM numeral system).
It is possible to define MAX(M,M’) and MIN(M,M’) for the unary representation. We did not define it in the previous section, because at least MIN(M,M’) requires to alternate between running M and M’, which was not among the constructions defined there. Neither MAX(M,M’) nor MIN(M,M’) can be defined for any of our succinct representations. The reason is that already the first few digits of the result will determine whether M or M’ is bigger, but there are M and M’ where in one model of nsEFA it is M which is bigger, and in another model it is M’.
All our succinct representations allow conversion to the unary representation. Since MAX(M,M’) and MIN(M,M’) are defined for the unary representation, but not for our succinct representations, we conclude that conversion from the unary representation to any of our succinct representations is not possible. The fact that conversion to unary is possible also makes it easier to compare numbers defined by n-machines using different representations for equality: The numbers are equal if nsEFA can prove that the numbers which were converted to unary are equal.
Let REM(M,x) (or rather |REM(M,x)|) be the remainder  from the division of |M| by x such that
from the division of |M| by x such that 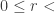 x. For the LCM numeral system and the factorial number system, we have that REM(M,x) can be defined for any standard natural number x. For the primorial number system, it can only be defined for any square-free standard natural number x. For binary, x must be a power of two, and for decimal, x must be a product of a power of two and a power of five. We conclude from this that binary cannot be converted to decimal, neither binary nor decimal can be converted to LCM, factorial, or primorial, and primorial cannot be converted into any other of our succinct representations.
x. For the LCM numeral system and the factorial number system, we have that REM(M,x) can be defined for any standard natural number x. For the primorial number system, it can only be defined for any square-free standard natural number x. For binary, x must be a power of two, and for decimal, x must be a product of a power of two and a power of five. We conclude from this that binary cannot be converted to decimal, neither binary nor decimal can be converted to LCM, factorial, or primorial, and primorial cannot be converted into any other of our succinct representations.
What about the remaining conversions between our succinct representations that we have not ruled out yet? If we know the lowest i digits of the decimal representation, then we can compute the lowest i digits of the binary representation. Therefore, we conclude that decimal can be converted to binary. In theory, we would have to check that nsEFA can actually prove that directly converting a decimal nummber to unary gives the same number as first converting it to binary and then to unary. But who cares?
To compute the lowest i digits of the binary representation, it is sufficient to know the lowest 2i digits of the factorial representation, or the lowest 2i digits of the LCM representation. So factorial and LCM can be converted to binary. To compute the lowest i digits of the decimal representation, it is sufficient to know the lowest 5i digits of the factorial representation, or the lowest 5i digits of the LCM representation. So factorial and LCM can be converted to decimal. To compute the lowest π(i) digits of the primorial representation (where π(n) is the prime-counting function), it is sufficient to know the lowest i digits of the factorial or LCM representation. So factorial and LCM can be converted to primorial. To compute the lowest π(i) digits of the LCM representation, it is sufficient to know the lowest i digits of the factorial representation. To compute the lowest i digits of the factorial representation, it is sufficient to know the lowest ii digits of the LCM representation. So it is possible to convert LCM to factorial and factorial to LCM.
In the previous section, we defined ADD(M,M’), MUL(M,M’), POW(M’,M), SUB(M,x), DIV(M,x) and LOG(x,M) using the unary representation. ADD(M,M’), MUL(M,M’), and SUB(M,x) can be defined for any of our succinct representations, LOG(x,M) for none. For the LCM numeral system and the factorial number system, we have that DIV(M,x) can be defined for any standard natural number x. For binary, x must be a power of two, and for decimal, x must be a product of a power of two and a power of five. This is the same as for REM(M,x). But for primorial, DIV(M,x) cannot be defined at all, not if x is square-free (even so this is sufficient for REM(M,x) to be defined), not even if x is a prime number.
What about POW(M’,M)? We have  , where
, where 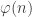 is Euler’s totient function. Therefore POW(M’,M) can be defined for the LCM numeral system and the factorial number system, but not for any other of our succinct representations, not even in case |M’|=2. What about other functions? There is a
is Euler’s totient function. Therefore POW(M’,M) can be defined for the LCM numeral system and the factorial number system, but not for any other of our succinct representations, not even in case |M’|=2. What about other functions? There is a
list of functions in the wikipedia article on primitive recursive functions. All those functions actually seem to be from ELEMENTARY, but that does not necessarily mean that they can be defined for one of our representations (not even unary). Maybe 4. Factorial a!, 11. sg(a): signum(a): If a=0 then 0 else 1, and 18. (a)i: exponent of pi in a are still interesting. The signum function can be definitively be defined for any of our representations. It seems that the factorial function too can be defined for any of our representations. It is interesting, because it will just output an infinite stream of zero digits for any non-standard natural number, for any of our succinct representations. Actually, our requirements for n-machines currently (see next section) don’t allow us to output an infinite stream of zero digits. However, there is a workaround: we can output the “overflow” digit instead of the first zero digit, and the “maximal” digits instead of the consecutive zero digits. The exponent of pi cannot be defined for unary. But we can define it as a function from the LCM or factorial representation to the unary representation.
So we have a nice collection of trivial facts about our succinct representations. But what are our succinct representations good for, compared to unary? After all, the representation is just an n-machine in both cases, and the n-machine for a succinct representation is not much shorter than the corresponding n-machine for the unary representation. Their runtime and output can be exponentially shorter, but EFA does not care about that either. There is at least one important advantage: The finite initial segments of output digits reveal more information than for unary, and that information is guaranteed to be present (which is not the case for unary). Turns out that for our succinct representation, this information is no more than the remainders of the division with all standard natural numbers (or a suitable infinite subset of the standard natural numbers).
But why is this advantage relevant? Why is our nice collection of trivial facts relevant? In terms of absolute truth, a given n-machine is on the one hand what nsEFA can prove about it, but on the other hand it is also a possibly infinite string of digits. The length of this string is bounded by the number of steps the n-machine performs before it stops. So we nearly succeeded in exposing the circularity of defining a natural number as a finite string of digits. The length of the string (in any of our succinct representations) is indeed a natural number, but only in unary representation. And it cannot (in general) be converted back to any of our succinct representations. Since we used EFA, it is nice that we found a succinct representations for which POW(M’,M) can be defined. Since Gödel’s β function 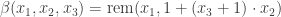 uses the remainder, it is nice that it can be defined. Since the exponent of pi is one way for encoding sequences into natural numbers, it is interesting that is can only be defined as a function from LCM or factorial to unary.
uses the remainder, it is nice that it can be defined. Since the exponent of pi is one way for encoding sequences into natural numbers, it is interesting that is can only be defined as a function from LCM or factorial to unary.
Conclusions?
One of the initial ideas was to construct a non-standard model of EFA, or more precisely a model of nsEFA. This was not achieved. What has been achieved is a very concrete description of some non-standard numbers by Turing machines which do not halt in terms of absolute truth, but for which nsEFA proves that they halt. Those non-standard numbers define unique numbers in any model of nsEFA, and we ensured that it cannot happen that those numbers define different standard natural numbers in different models. We settled on an obvious way to compare those non-standard numbers for equality, and explained why we won’t be able to achieve our initial goal. We decided to go on with the post nevertheless, and show that addition, multiplication, and exponentiation can be defined for those numbers. We then started to dive deeply into technical details, till the point were a section got so technical that most of its content got removed again, because this is supposed to be a more or less straightforward and readable blog post after all.
Anyway, the most important thing about the natural numbers is the ability to write recursions. That’s kind of the defining property, really. You have to be able to do predecessor and comparison to zero or it’s not a good encoding, IMO.
This was a reaction to a previous attempt to explain that the encoding of natural numbers can be important. It has a valid point. Focusing on addition, multiplication, and exponentiation seemed to make sense from the perspective suggested by EFA, but recursion and induction should not have been neglected. On the other hand, Robinson arithmetic completely neglects recursion and induction, our non-standard number seem to be a model of it, and people still treat it as closely related to the natural numbers.
The main idea of this post was to use the natural number implicitly defined by a Turing machine which halts (or for which some axiom system claims that it halts) as the length of a string of digits. This idea turned out to work surprisingly well. The purpose was to illustrate how defining a natural number as a finite string of digits is circular. This was achieved, in a certain sense: We were naturally lead to define operations like SUB(M,x), DIV(M,x), MIN(M,M’), REM(M,x), and the exponent of pi in M. Those operations require three different kinds of natural number: standard natural numbers (those for which EFA can prove that the machine halts), numbers in succinct representation, and numbers in unary representation. SUB and DIV work for both unary and succinct, but the second argument must be standard. MIN only works for unary, and REM only works for succinct. The last one only works as a function from succinct to unary, where pi must be standard.
Were we really naturally lead there, or did some of our previous decisions lead us there, like to only allow those M which halt or output infinitely many non-zero digits? Well, yes and no. The decision to forbid non-standard numbers which are undecided about whether they are equal to a given standard number probably had some impact. At least it would have been more difficult otherwise to argue why certain functions cannot be defined. The specific way how we enforced this decision had no impact on the definability of the functions we actually investigated, and it is unclear whether it could have had in impact.
It did have a minor impact on our succinct representations, but in the end the “overflow” digit is only a minimal modification. It does offer some parallel speedup for addition, but signed digits are necessary to get good parallel speedup for multiplication. Those can be signed digits can be interpreted as a (a-b) representation (of integer numbers), and lures one into trying to find something close to the (c/d) representation (of rational numbers) which might allow good parallel speedup for division or exponentiation. (Well, that hope actually comes from a paper on Division and Iterated Multiplication by W. Hesse, E. Allender, and D. Barrington which says in section 4: “The central idea of all the TC0 algorithms for Iterated Multiplication and related problems is that of Chinese remainder representation.”) This lead to including the factorial and primorial representation in the succinct representations, and in trying to “fix” the primorial representation by including the LCM representation.
Appendix A: Initial questions about circularity and the idea for this post
Of course Hume is right that justifying induction by its success in the past is circular. Of course Copenhagen is right that describing measurements in terms of unitary quantum mechanics is circular. Of course Poincaré is right that defining the natural numbers as finite strings of digits is circular. …
But this circularity is somehow trivial, it doesn’t really count. It does make sense to use induction, describing measurement in terms of unitary quantum mechanics does clarify things, and the natural numbers are really well defined. But why? Has anybody ever written a clear refutation explaining how to overcome those trivial circularities? …
So I wondered how to make this more concrete, in a similar spirit like one shows that equality testing for computational real numbers is undecidable. The idea here is to take some Turing machine for which we would like to decide whether it halts or not, and write out the real number 0.000…000… with an additional zero for every step of the machine, and output one final 1 when (and only if) the machine finally halts. Deciding whether this real number is equal to zero is equivalent to solving the halting problem for the given Turing machine. How can one do something similarly concrete for natural numbers? Suppose that you have a consistent (but maybe unsound/dishonest) axiom system that claim that some given Turing machine would halt. Then this Turing machine defines a natural number in any model of that axiom system. To expose the trivial circularity, we can now use this natural number to define the length of a finite string of digits. How do we get the digits themselves? We can just use any Turing machine which outputs digits for that, independent of whether it halts or not. Well, maybe if it doesn’t halt, it would still be interesting whether it will output a finite or an infinite number of digits, but in the worst case we can ask the axiom system again about its opinion on this matter. The requirement here is that the natural numbers defined in this way should define a natural number in any model of that axiom system.
Appendix B: What are we allowed to assume?
It might seem strange to cast doubt on whether the concept of a natural number is non-circular, but at the same time taking Turing machines and axiom systems for granted. An attempt at an explanation why natural numbers are a tricky subject (in logic) was made in a blog comment after the line Beyond will be dragons, formatting doesn’t work… The bottom line is that it is possible to accept valid natural numbers, but not possible to reject (every possible type of) invalid natural numbers. So what should we allow ourselves to assume and what not? Specific natural numbers, Turing machines, and axiom systems can be given, since we can accept them when they (or rather their descriptions) are valid. A Turing machine can halt, and an axiom system can prove a given statement. This also means that we can talk about an axiom system being inconsistent, since this just means that it proves a certain statement. Talking about an axiom system being consistent is more problematic. We have done it anyway, because this appendix was only added after the post was already finished (based on feedback from Timothy Chow). We did try to avoid assuming that arbitrary arithmetical sentences have definitive truth values, and especially tried to avoid using oracle Turing machines.
However, in the end we are trying to construct a concrete model of an unsound/dishonest axiom system. Such an axiom system can have an opinion about the truth values of many arbitrary arithmetical sentences. So if it would have helped, we would have had no problem to assume that arbitrary arithmetical sentences have definitive truth values. And assuming consistency definitively helps when you are trying to constuct a model, so we just assumed that it was unproblematic.
Appendix C: Weakening the requirements for succinct representations
We did not use the “overflow” digit much in discussing our succinct representations. But we simply did not go into details of addition and multiplication. The previous post on signed digit representations focused more on details. It explained for example why having signed digits is even better than having an “overflow” digit for the speed of multiplication. At the point were we introduced the requirement to output infinitely many non-zero digits (which made the “overflow” digit necessary), we postponed the discussion of alternatives.
Let us try to weaken our requirements instead of having to invent new representation systems. We could forbid trailing zeros (or only allow a finite number of trailing zeros). This is meaningless in terms of absolute truth, since it is meaningless to talk about the trailing zeros if the machine M outputs infinitely many digits. What we want to express is that “if M would halt, then there would be no trailing zeros (or no more trailing zeros than a given finite number)”. So we are fine if nsEFA can prove this, since our requirements only need to ensure that non-standard natural numbers cannot mix with standard natural numbers. A slight refinement is to require that nsEFA must prove for a concrete function tf(n) which can be proved total in EFA that if M outputs more than tf(“total number of steps of M when previous non-zero digit was output”) consecutive zeros, then it will output at least one further non-zero digit before it halts. This refinement tries to ensure that a machine M valid according to our initial requirements is also valid according to our weakened requirements.
Appendix D: Some questions this post failed to answer
The section on comparing numbers for equality showed that our plan for constructing a concrete non-standard model of EFA will not work as intended. But this leaves open some questions, since we did construct a concrete stucture:
- The totality of the order relation obviously fails. But our concrete structure still seems to be a model of Robinson arithmetic. Does it also satisfy induction on open formulas? It is not obvious why induction on open formulas should fail.
- Is there some non-concrete equivalence relation on our structure such that the resulting quotient structure would be a model of nsEFA? Can we just take any consistent negation complete extension of nsEFA, and identify those n-machines for which that extension proves that they produce the same output? At least we are not guaranteed to get a model of that extension, because it will (in general) prove that more Turing machines halt than we have included in our structure. (Even worse, the extension has an opinion about arbitrary arithmetical sentences, so we might even have to include oracle Turing machines in our structure, if we wanted to get a model of that extension.) So the resulting quotient structure might not satisfy the induction scheme of nsEFA. Still, the order relation would be total, and the remainder (for a standard natural number) would be defined.
- In a certain sense, the free algebra is a canonical model of an equational theory. The straight-line program encoding is natural for storing the elements of the free algebra. But nsEFA does not have a canonical model, and the straight-line program encoding of natural numbers might rather feel deliberately perverse. Some people really do not understand why you would want to ever consider this as an encoding of natural numbers. And with respect to the natural numbers, the straight-line program encoding may indeed be inappropriate. So our efforts might be interpreted as an attempt to find appropriate encodings which can take over the role of straight-line program encodings in case of nsEFA. But can we make it more precise in which way our n-machines provide appropriate substitutes for the elements of the non-existing free algebra? Who knows, maybe if we tried hard enough, we would find reason why we cannot do that.
Appendix E: More on the LCM numeral system
As said before, we did not actually talk much about arithmetic in the LCM or factorial representation. Let me copy a discussion about division for factorial and LCM, and relatively fast multiplication for LCM below, to talk at least a bit about those topics:
If an arbitrarily huge number is divided by a fixed number  (assumed to be small), then the factorial number system only needs to know the lowest
(assumed to be small), then the factorial number system only needs to know the lowest  digits of the huge input number for being able to write out the lowest
digits of the huge input number for being able to write out the lowest  digits of the result. The LCM number system also only need to look ahead a finite number of digits for writing out the lowest digits of the result. The exact look ahead is harder to determine, it should be more or less the lowest
digits of the result. The LCM number system also only need to look ahead a finite number of digits for writing out the lowest digits of the result. The exact look ahead is harder to determine, it should be more or less the lowest 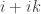 lowest digits of the huge input number.
lowest digits of the huge input number.
However, the LCM number system also has advantages over the factorial number system. Just like the primorial number system, it allows a simple and relatively fast multiplication algorithm. The numbers can be quickly converted into an optimal chinese remainder representation and back:
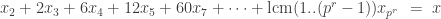 with
with 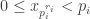 .
.
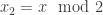


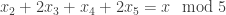
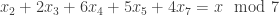
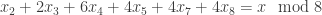
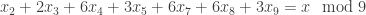

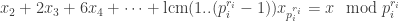
So to multiply  and
and  , one determines an upper bound for the number of places of
, one determines an upper bound for the number of places of 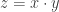 , then computes value of and modulo all those places, multiplies them separately for each place (modulo
, then computes value of and modulo all those places, multiplies them separately for each place (modulo  ), and then converts the result back to the LCM representation. The conversion back is easy, since one can first determine
), and then converts the result back to the LCM representation. The conversion back is easy, since one can first determine 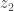 , then
, then 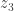 by subtracting from the known value
by subtracting from the known value 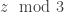 before converting it to , then
before converting it to , then  by subtracting
by subtracting 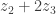 from the known value
from the known value  before converting it to , and so on.
before converting it to , and so on.
This chinese remainder representation is optimal in the sense that the individual moduli are as small as possible for being able to represent a number of a given magnitude. The LCM number system may be even more optimal than the primorial number system in this respect. (It should be possible to do the computations modulo only for the biggest  , due to the structure of the LCM number system.)
, due to the structure of the LCM number system.)

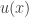





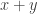



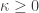 ,
,  ,
, 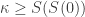 , …,
, …, 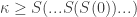 , … to PA. Then
, … to PA. Then  is a non-standard integer, and any non-standard model of PA will contain such a
is a non-standard integer, and any non-standard model of PA will contain such a 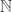 and only
and only  to get an axiomatization of the standard integers.
to get an axiomatization of the standard integers.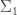 – and
– and 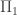 -sentences as axioms to PA, the result would still be a first-order theory, and hence there would still be non-standard models. And there would still be undecidable
-sentences as axioms to PA, the result would still be a first-order theory, and hence there would still be non-standard models. And there would still be undecidable 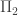 -sentences in that theory, so there would be a non-standard model with a number represented by a non-quasihalting TM. (So an oracle for quasihalting TMs in that non-standard model would be forced to sometimes lie by taking forever to describe the TM, or more precisely by providing a TM with a non-standard number of states.)
-sentences in that theory, so there would be a non-standard model with a number represented by a non-quasihalting TM. (So an oracle for quasihalting TMs in that non-standard model would be forced to sometimes lie by taking forever to describe the TM, or more precisely by providing a TM with a non-standard number of states.) sets also correspond to those which are limit computable in the sense of Putnam and Shoenfield (see, e.g., Soare 2016, §3.5). In other words
sets also correspond to those which are limit computable in the sense of Putnam and Shoenfield (see, e.g., Soare 2016, §3.5). In other words  is
is  – i.e. one for which membership can be determined by following a guessing procedure which may make a finite number of initial errors before it eventually converges to the correct answer.
– i.e. one for which membership can be determined by following a guessing procedure which may make a finite number of initial errors before it eventually converges to the correct answer.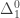 -definable sets are the computable sets, the
-definable sets are the computable sets, the 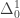 -definable sets are the arithmetical sets (
-definable sets are the arithmetical sets (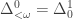 ), and the
), and the 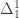 -definable sets are the hyperarithmetical sets. The limit computable sets are “slightly more complex” than the computable sets, but less “complex” than the arithmetical sets. I recently
-definable sets are the hyperarithmetical sets. The limit computable sets are “slightly more complex” than the computable sets, but less “complex” than the arithmetical sets. I recently 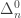 classes as classes of subsets of natural numbers allows nice identifications like
classes as classes of subsets of natural numbers allows nice identifications like 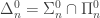 , but it also hides their true nature. They are classes of partial functions from finite strings to finite strings (or from
, but it also hides their true nature. They are classes of partial functions from finite strings to finite strings (or from  for such classes of partial function, in the context of the polynomial hierarchy. Those computable partial functions can be defined by adding an
for such classes of partial function, in the context of the polynomial hierarchy. Those computable partial functions can be defined by adding an 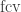 (or a finally-constant-after operator
(or a finally-constant-after operator  if one wants to stay closer to the μ-operator) to a suitable set of basic operations. Using a natural number
if one wants to stay closer to the μ-operator) to a suitable set of basic operations. Using a natural number 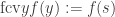 . Using
. Using 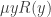 can be defined in terms of the bounded μ-operator
can be defined in terms of the bounded μ-operator 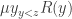 as
as 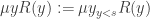 . One could
. One could 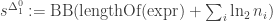 and
and  , where BB is the busy beaver function, and BBB is the beeping busy beaver function. Then
, where BB is the busy beaver function, and BBB is the beeping busy beaver function. Then 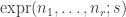 will give the “correct” result for computable functions if
will give the “correct” result for computable functions if  , and the “correct” result for limit computable functions if
, and the “correct” result for limit computable functions if  . Because such a function is not necessarily defined for all
. Because such a function is not necessarily defined for all 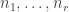 , the exact meaning of “correct” needs elaboration. For limit computable functions, the function is defined for
, the exact meaning of “correct” needs elaboration. For limit computable functions, the function is defined for 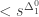 must be used instead. Note that for a given natural number N, both BB(N) and BBB(N) can be represented by a concrete Turing machine with N states, which means that the length of its description is of order O(N log(N)), i.e. quite short. But there is a crucial difference: the Turing machine describing BB(N) can be used directly to determine whether a concretely given natural number is smaller, equal or bigger than it, because it is easy to know when BB(n) stopped. But BBB(N) is harder to use, because how should we know whether it will never beep again? OK, each time it beeps, we learn that BBB(N) is greater or equal to the number of steps performed so far. If we had access to BB(.), we could could encode the current state of the tape into a Turing machine T which halts at the next beep, and then use BB(nrStatesOf(T)) to check whether it halts. However, the size of that state will grow while letting BBB(N) run, so that in the end we will need access to BB(N+log(BBB(N)).
must be used instead. Note that for a given natural number N, both BB(N) and BBB(N) can be represented by a concrete Turing machine with N states, which means that the length of its description is of order O(N log(N)), i.e. quite short. But there is a crucial difference: the Turing machine describing BB(N) can be used directly to determine whether a concretely given natural number is smaller, equal or bigger than it, because it is easy to know when BB(n) stopped. But BBB(N) is harder to use, because how should we know whether it will never beep again? OK, each time it beeps, we learn that BBB(N) is greater or equal to the number of steps performed so far. If we had access to BB(.), we could could encode the current state of the tape into a Turing machine T which halts at the next beep, and then use BB(nrStatesOf(T)) to check whether it halts. However, the size of that state will grow while letting BBB(N) run, so that in the end we will need access to BB(N+log(BBB(N)). and
and 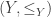 is given by
is given by 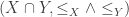 . Or more general, since a binary product is not enough for our purposes, the product of a family
. Or more general, since a binary product is not enough for our purposes, the product of a family  of partial orders should be given by
of partial orders should be given by 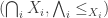 .
. is a set and
is a set and 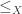 is a reflexive, antisymmetric, and transitive binary relation on
is a reflexive, antisymmetric, and transitive binary relation on  for any objects
for any objects 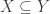 and
and 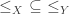 . (The binary relation
. (The binary relation 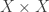 .)
.) to the category of sets. It is
to the category of sets. It is  on objects and
on objects and 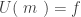 with
with  on morphisms
on morphisms 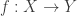 whose domain
whose domain  , and which are the identity on their domain.
, and which are the identity on their domain.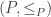 be a given partial order. Then for any two elements
be a given partial order. Then for any two elements  with
with 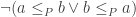 take the transitive closure of the partial order where
take the transitive closure of the partial order where  is added and the transitive closure or the partial order where
is added and the transitive closure or the partial order where  is added, and extend both to a total order on
is added, and extend both to a total order on  . The product of all those total order (two for each
. The product of all those total order (two for each 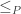 .
. by
by  , then the
, then the 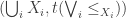 (note that the family must be small, i.e. a set). (See non-existing Appendix B, or a follow-up post.) Any Bool-category also trivially has coequalizers, so the Bool-category of preorders has all limits and all small colimits.
(note that the family must be small, i.e. a set). (See non-existing Appendix B, or a follow-up post.) Any Bool-category also trivially has coequalizers, so the Bool-category of preorders has all limits and all small colimits. is a set
is a set 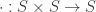 which is associative:
which is associative: 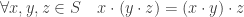 . To simplify notation, concatenation is used instead of
. To simplify notation, concatenation is used instead of  and parentheses are omitted.
and parentheses are omitted.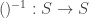 such that:
such that: 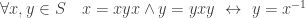 . An element
. An element 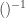 is preserved automatically due to its characterization purely in terms of multiplication.
is preserved automatically due to its characterization purely in terms of multiplication.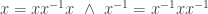 and
and  . The first identity says that
. The first identity says that  is an inverse element of
is an inverse element of 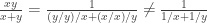 raise the question how easy or difficult it is to compute in commutative inverse rings. A partial answer is that the
raise the question how easy or difficult it is to compute in commutative inverse rings. A partial answer is that the  that every element is comparable with every other element is not universal Horn. For fields, the axiom
that every element is comparable with every other element is not universal Horn. For fields, the axiom 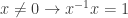 that non-zero elements are cancelative is not universal Horn. Those axioms also prevent the term interpretation from being a total order, respectively a field.)
that non-zero elements are cancelative is not universal Horn. Those axioms also prevent the term interpretation from being a total order, respectively a field.) be a homomorphism between models
be a homomorphism between models 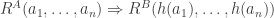 and
and  for all relational symbols
for all relational symbols  ?
?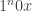 would have to be adapted too.
would have to be adapted too.
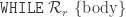



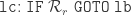
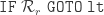
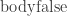
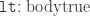
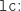
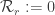
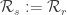

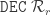
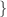
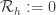

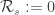




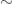 is defined via
is defined via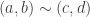 iff
iff 
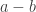 . This motivates the signed-digit representation. To avoid storing two numbers instead of one, the subtraction gets performed on the level of digits. This leads to signed digits. The overhead can be kept small by using unsigned 7-bit or 31-bit digits as starting point (instead of decimal or binary digits).
. This motivates the signed-digit representation. To avoid storing two numbers instead of one, the subtraction gets performed on the level of digits. This leads to signed digits. The overhead can be kept small by using unsigned 7-bit or 31-bit digits as starting point (instead of decimal or binary digits). , we could also write
, we could also write