A deterministic finite automaton (DFA)  is a 5-tuple,
is a 5-tuple, 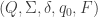 , consisting of
, consisting of
- a finite set of states

- a finite set of input symbols

- a (partial) transition function
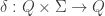
- an initial state
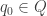
- a set of accept states
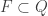
An isomorphism between two DFAs 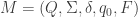 and
and  is a bijection
is a bijection  such that
such that  ,
,  and
and 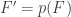 .
.
Isomorphism of DFA is GI complete
Without further restrictions, the problem of testing whether two DFAs and 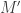 are isomorphic is as difficult as testing whether two graphs
are isomorphic is as difficult as testing whether two graphs  and
and 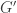 are isomorphic, i.e. the problem is GI complete. A simple construction shows that the problem of testing whether two digraphs and are isomorphic reduces to DFA isomorphism testing.
are isomorphic, i.e. the problem is GI complete. A simple construction shows that the problem of testing whether two digraphs and are isomorphic reduces to DFA isomorphism testing.
For a digraph 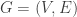 , construct the DFA
, construct the DFA 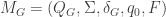 with
with 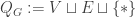 ,
, 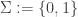 ,
,  ,
, 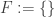 and
and 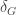 defined for
defined for  by
by 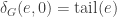 ,
, 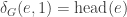 and for
and for  by
by  .
.
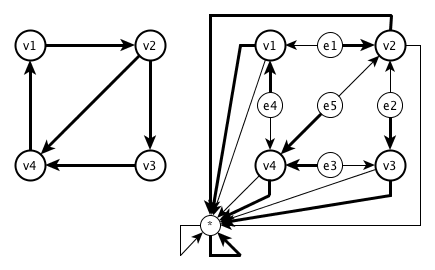
Obviously, the digraphs and are isomorphic iff the DFAs  and
and  are isomorphic.
are isomorphic.
A canonical labeling technique
A reasonable restriction is to require that every state in is reachable from  . Let
. Let  . Then a unique labeling
. Then a unique labeling 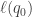 of can be produced by a breadth first search of starting at as follows: You have a queue (first-in, first-out store), initially containing only . Repeatedly do this: remove the state at the head of the queue, say
of can be produced by a breadth first search of starting at as follows: You have a queue (first-in, first-out store), initially containing only . Repeatedly do this: remove the state at the head of the queue, say  , then push into the queue (at the tail) those of
, then push into the queue (at the tail) those of  (in that order) which have never previously been put into the queue. Since every state is reachable from , every state is put into the queue eventually. Stop when that has happened and define to be the order in which states were put into the queue. Since this labeling is independent of any ordering or labeling of , it fixes the only bijection between and
(in that order) which have never previously been put into the queue. Since every state is reachable from , every state is put into the queue eventually. Stop when that has happened and define to be the order in which states were put into the queue. Since this labeling is independent of any ordering or labeling of , it fixes the only bijection between and  that can possibly lead to an isomorphism between and . It is easy then to check whether they are actually isomorphic.
that can possibly lead to an isomorphism between and . It is easy then to check whether they are actually isomorphic.
Attributing that algorithm to Brendan McKay would be misleading, because it is so obvious. For example J.-E. Pin described the same algorithm (using depth first search instead of breadth first search) earlier, as an answer to a question about finding an isomorphism between finite automata.
Brendan McKay’s canonical labeling technique
The context in which Brendan McKay described his canonical labeling technique was actually slightly more complicated, because there was no distinguished state , and the state space of the automaton wasn’t required to be weakly connected. But instead,  was injective for all
was injective for all  . If we drop the requirement that is a total function and allow it to be partial, then we end up exactly with the reversible deterministic finite automata, described earlier on this blog. Brendan McKay’s technique generalizes effortlessly to this setting, as does the original context (where group actions are replaced by inverse semigroup actions).
. If we drop the requirement that is a total function and allow it to be partial, then we end up exactly with the reversible deterministic finite automata, described earlier on this blog. Brendan McKay’s technique generalizes effortlessly to this setting, as does the original context (where group actions are replaced by inverse semigroup actions).
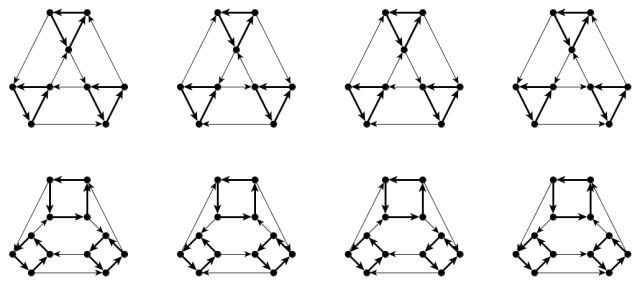
Above are some colored digraphs corresponding to reversible deterministic finite automata (the initial state and the final states  are ignored). We continue to describe the canonical labeling technique in terms of deterministic finite automata. For each state
are ignored). We continue to describe the canonical labeling technique in terms of deterministic finite automata. For each state 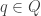 , we can produce a unique labeling
, we can produce a unique labeling  (of the weakly connected component containing
(of the weakly connected component containing  ) by a breadth first search of starting at as above, expect when we remove the state from the head of the queue, (instead of ) we have to push into the queue (at the tail) those of
) by a breadth first search of starting at as above, expect when we remove the state from the head of the queue, (instead of ) we have to push into the queue (at the tail) those of 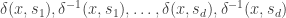 (in that order) which are defined and have never previously been put into the queue.
(in that order) which are defined and have never previously been put into the queue.
But how can we create a canonical labeling of from the unique labelings ? Just take (one of) the lexicographically smallest labelings of each block, and sort the block lexicographically based on those labelings. The lexicographical order in this context is defined by encoding a labeled block in some reasonable (unique) way as a string, and comparing those strings lexicographically. It’s a good idea to modify this lexicographical order to first compare the lengths of the strings, but this is already an optimization, and there are more possible optimizations, as described in Brendan’s answer. These optimizations are the context of the following remark at the end of his answer:
The graph is actually a deterministic finite automaton (at most one edge of each colour leaves each vertex). There could be faster isomorphism algorithms out there for DFAs, though I’m dubious that anything would work faster in practice than a well-tuned implementation of the method I described.
This remark was actually the main motivation of this blog post, i.e. to investigate the relation of Brendan’s technique to isomorphism testing for DFAs. If there were really faster isomorphism algorithms out there for DFAs, then either they would not be applicable to the problem which Brendan had solved there (if they rely on reachability from ), or they would also solve GI itself in polynomial time (which is highly unlikely).
Conclusions?
The truth is I have been yak shaving again, even so I explicitly told vzn that I didn’t want to get too involved with GI. How did it happen? Fahad Mortuza (aka Jim) asked me for help refuting his attempts to solve GI in quasipolynomial time. (This is completely unrelated to the recent breakthrough by László Babai, except maybe that he triggered some people to spend time on GI again.) While working with him, I realized that permutation group isomorphism might be more difficult than group isomorphism, and asked some questions to get a better feeling for the relation of permutation group isomorphism to GI. The idea to consider the case where the group is fixed came from reading an introduction to category theory, because those morphisms of left -sets felt like cheating (or oversimplifying) to me. So I guessed that this case should be easy to solve, if I would only understand how Brendan McKay handles automorphisms of graphs efficiently. Then Brendan McKay himself explained his technique (for this case) and I discovered the interesting connection to inverse semigroups and finite automata, so I decided I had to write a blog post on this. Now I have written this post, just to avoid having another item on my ToDo list which never gets done.



💡 a new idea thinking about this. could FSM theory be leveraged against GI somehow? in particular it seems like (building on all this) DFA minimization might somehow be a natural way to test for GI. hmmm…..
Well, the first step of DFA minimization is to throw away all states not reachable by the initial state. For the DFA constructed above, only the initial state will be left. So we can’t use DFA minimization to test for GI.
will be left. So we can’t use DFA minimization to test for GI.
But DFA minimization can be used to highlight an interesting point. We could ask why GI is important, and how it relates to equivalence (or identity) testing for computational structures like DFA or straight line programs. Even so these tasks look more complicated than GI, the fastest known algorithm for GI takes quasi-polynomial time, while equivalence testing of DFA can be done in quasi-linear time, and identity testing of straight line programs can be done randomized in polynomial time. But the last step for equivalence testing of DFA after DFA minimization is indeed isomorphism testing for the minimized DFAs. And because every state is reachable from the initial state for these minimized DFAs, we see that these DFAs can be tested for isomorphism in linear time, by the technique described above.
think there is some broad theory that could be devised here, mused on this many years ago & its cool this post reminds me of it. youve made the basic observation that canonical graph labellings create basically DFA objects. my rough idea from many years ago is that some canonical graph labellings seem to lead to a natural algorithm for isomorphism based on DFA minimization. my vague ideas for the algorithm were something like:
a. canonically label the two graphs using some scheme X.
b. do DFA minimization on each graph. if there is a mismatch in vertex degree distribution, graphs are not isomorphic.
c. then compute if the DFAs are equivalent using intersection emptiness/ complement testing. (DFA A in DFA B iff A in B and B in A). if they are not equal, conclude graphs are not isomorphic.
d. conclude graphs are isomorphic.
then the natural question is, what are labelling schemes X that lead to this being a reliable isomorphism algorithm? in the sense of low false positives and negatives? do such schemes exist? is there a scheme that “always” works without false positives/negatives?
Pingback: Learning category theory: a necessary evil? | Gentzen translated